
Despite the best efforts of IT administrators around the world, there are still frequent reports in the media about IT outages. Many people reading this will have their own recent experience with unplanned downtime. Recent high-profile outages include major mobile service providers and cloud-based hosting services. No IT business is immune to service outages.
Over the years, many technologies and techniques have been used to prevent outages: redundant parts in servers, separate dual power connections, multiple networking paths from servers to switches and routers. Highly redundant disk storage arrays. Failover clusters. And remote backup systems on other sites. To highlight just a subset of what has been used.
Yet outages are still happening. Why is this? Some fatalists would say that it is just physics, and as IT systems run on physical hardware, then at some point failures are inevitable. They may have a point. But we can, and should, strive to eliminate unplanned outages affecting application availability as much as possible. Getting as many nines as we can in the uptime percentage figures is a worthy goal.
Preventing outages requires knowledge of what frequently causes them, and then learning how to mitigate the risks. Let’s take a look at the leading causes of outages, as reported in the ITIC 2020 Global Server Reliability Report.
Main Causes of Downtime
The ITIC report lists 15 reasons for downtime and outages. The chart below shows the top seven. The other eight categories recorded were selected by 19% down to 9% of respondents. I’ve excluded them here as most are subsets of the main types shown in the chart. See the full report for more details.
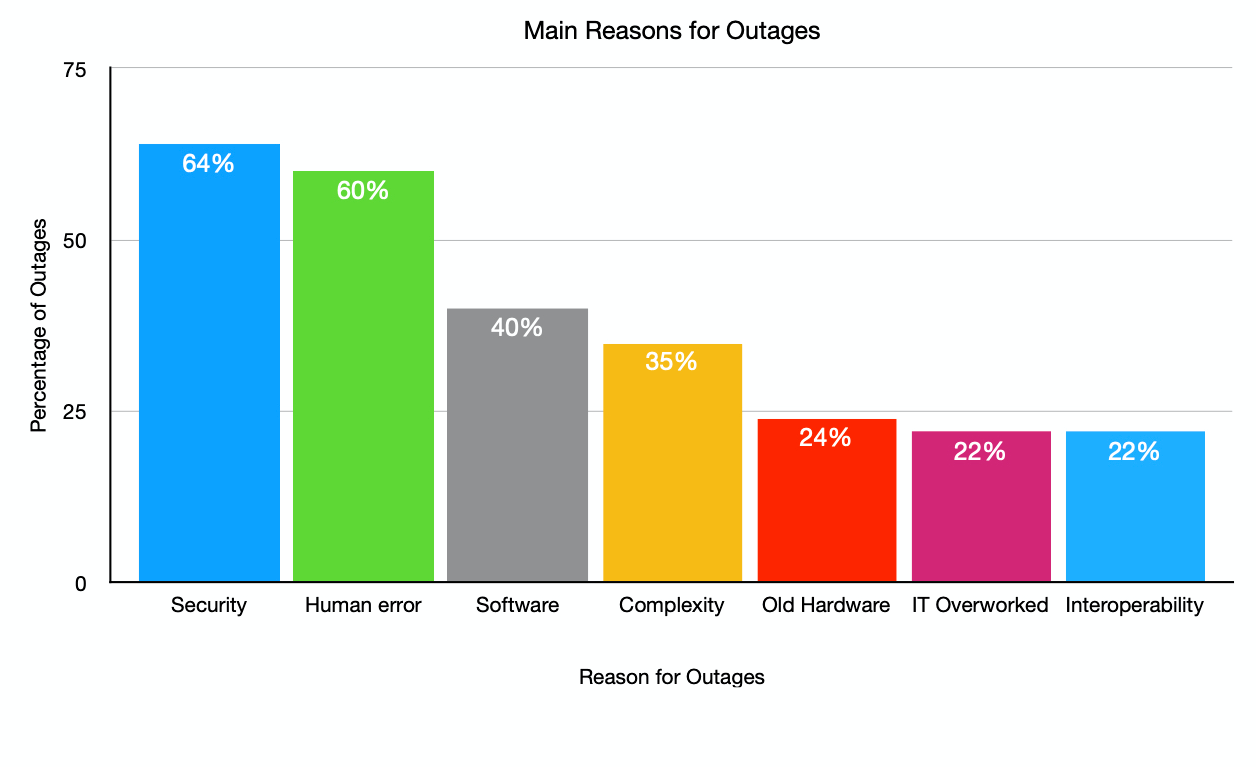
It won’t be a surprise to anyone that security and human error are the main reasons for outages among the 1200 organizations who responded for the ITIC report. With software issues and configuration complexity not far behind.
All these outage causes are related. Security attacks can be the result of human error when updating systems with patches. Or not updating them in some cases. Software faults that cause outages are often fixed in bug releases or upgrades that haven’t been deployed yet. Complexity in a systems UI is also linked to human error. Often it is not the human’s fault, as the UI on many systems is awful, especially on control systems for plant machinery and sophisticated operational technology (OT) that controls infrastructure.
Mitigating Outages
There is no single remedy to avoid outages. But let’s not surrender to the view of the fatalists. There are plenty of steps that can be taken to reduce them. With the ultimate, if maybe unattainable goal, of never having unplanned downtime.
One simple thing that can be done is to ensure that recurring software licenses for software and critical security certificates get renewed. One of the large UK service providers had a major outage due to a digital certificate expiring. If you are a CIO or other person responsible for IT systems in an organization, find out when your certificates and other software licenses expire. If possible, set them to auto-renew. If that is not possible, set a calendar alert for two weeks before each will expire. To remind you to renew them!
Eliminating outages due to security problems can be reduced by making sure that all systems are up to date with the latest patches. Applying patches to existing active systems can be troubling. The ‘If it isn’t broke, don’t fix it’, maxim often kicks in. To get patches applied to all systems as soon as possible have a complete test system available that mirrors the production layout as closely as possible. Test all patches there and get them into production with as small a gap between release and deployment as possible. In the interim, apply content security rules on your content security solution like a web application firewall (WAF). Doing this with cloud-based copies or digital twins of production systems is relatively straightforward.
Eliminating human error is hard. Humans are going to make errors. One way to mitigate this is to implement a Privileged Access Management (PAM) system. A PAM solution restricts access to critical systems and accounts to only those who need them. It also requires an approval workflow to be followed each time any administration work is done on a PAM protected system. Think of it like the dual keys needed to launch a missile in all good cold war films. PAM systems can also prevent dangerous command line and other admin activities from being run on systems. They also record and log all activity done under a PAM login. So that changes can be identified and quickly reversed if required.
Another way to eliminate human error is to preferentially choose tools that have a UI that is easier to use. Also, management systems that can integrate a wide range of systems into a single view that shows the current state of the whole network in a single pane of glass can highlight any errors made. Allowing them to be identified early and preventing them from causing an outage. Increasingly machine learning-based systems that learn typical behavior on the network and can quickly spot unusual traffic and behavior are being deployed.
Finally, building redundancy into IT system design to guard against outages is still required. It’s moved on from the days of dual power supplies, and dual network cards. Today with almost unlimited resources available in the public cloud, and global server load balancing available, organizations can spread their critical applications across the globe. If an outage occurs in a local data center or cloud host, all traffic can be routed to another site that is still functional, without any downtime for clients.
Conclusion
Preventing downtime will be an ongoing battle for the foreseeable future. Keeping systems up to date, making things easier for systems admin, and designing redundancy into the systems at the local and global level will all help to make outages as rare as possible.
